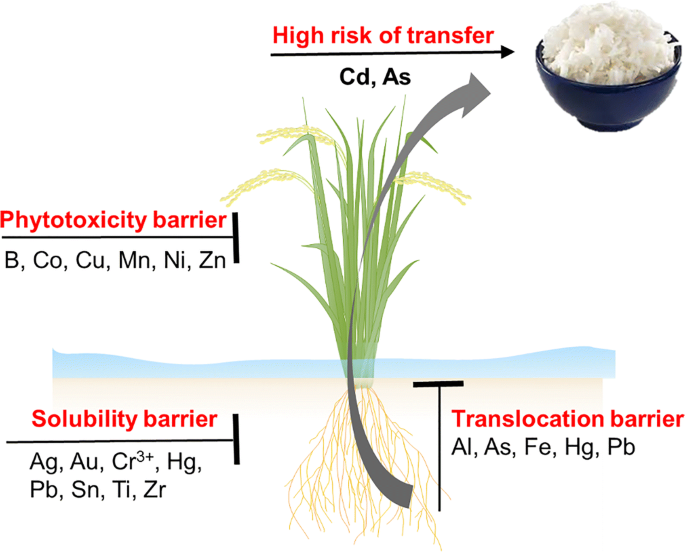
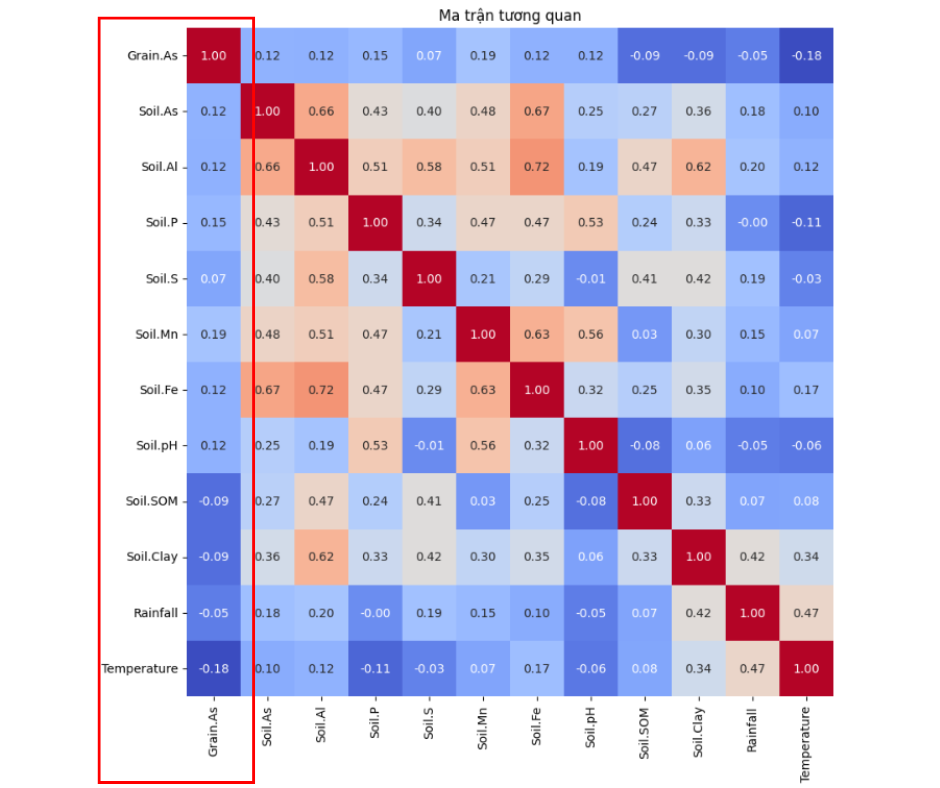
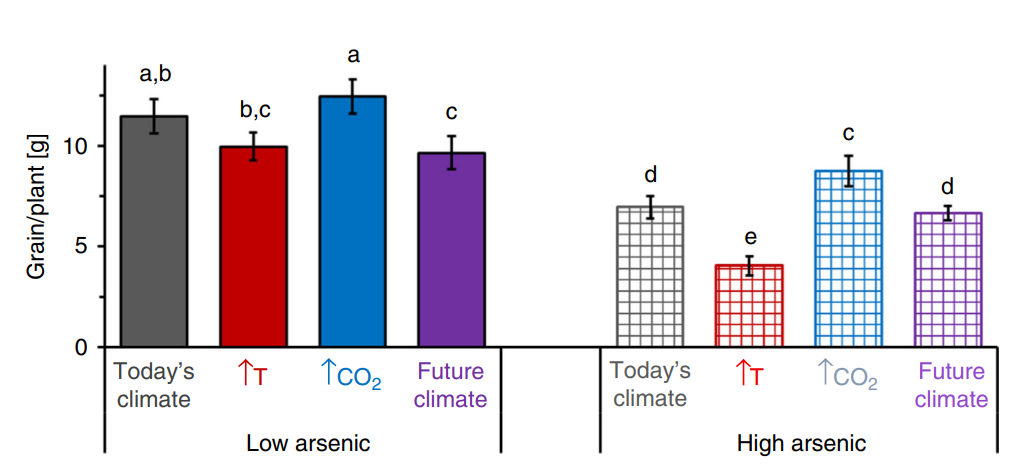
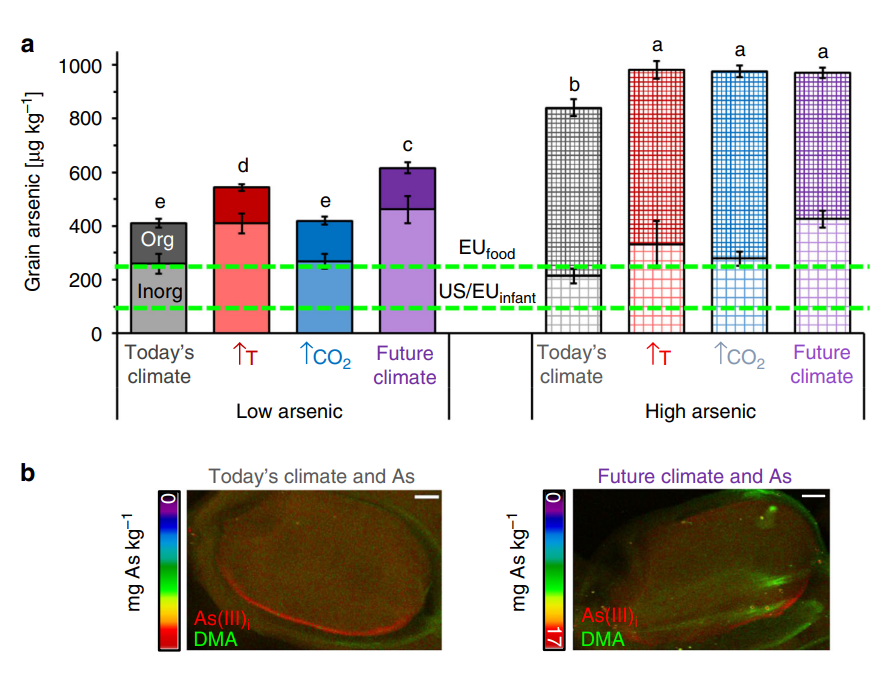
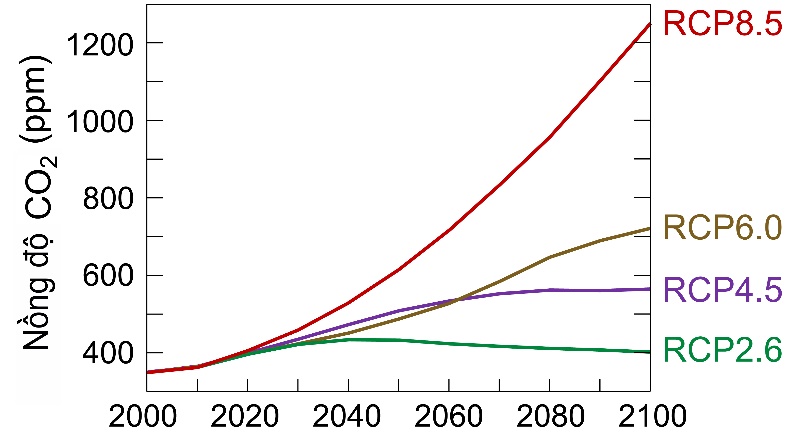
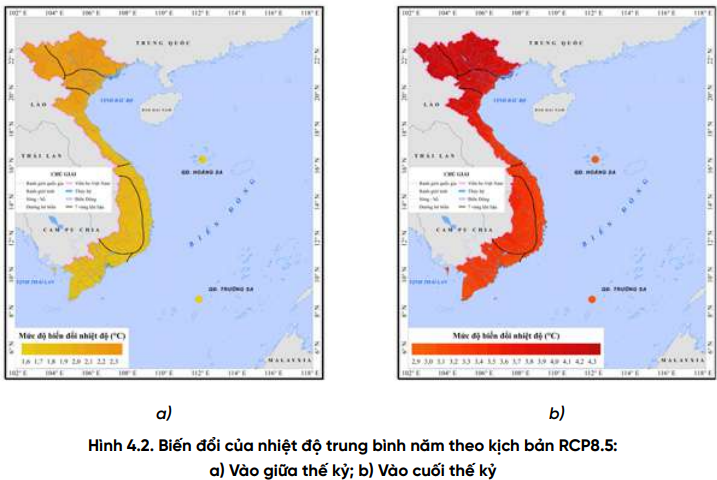
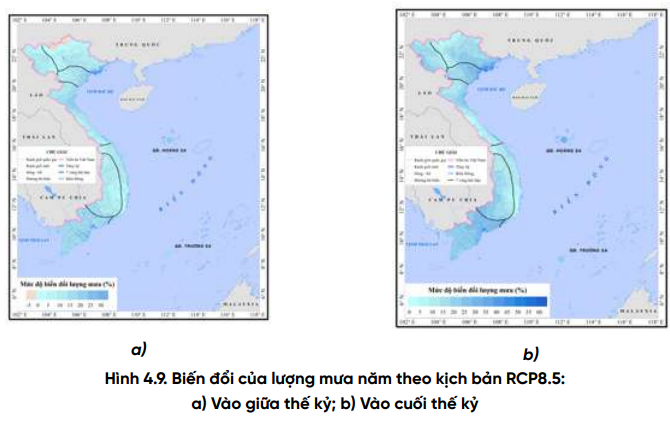
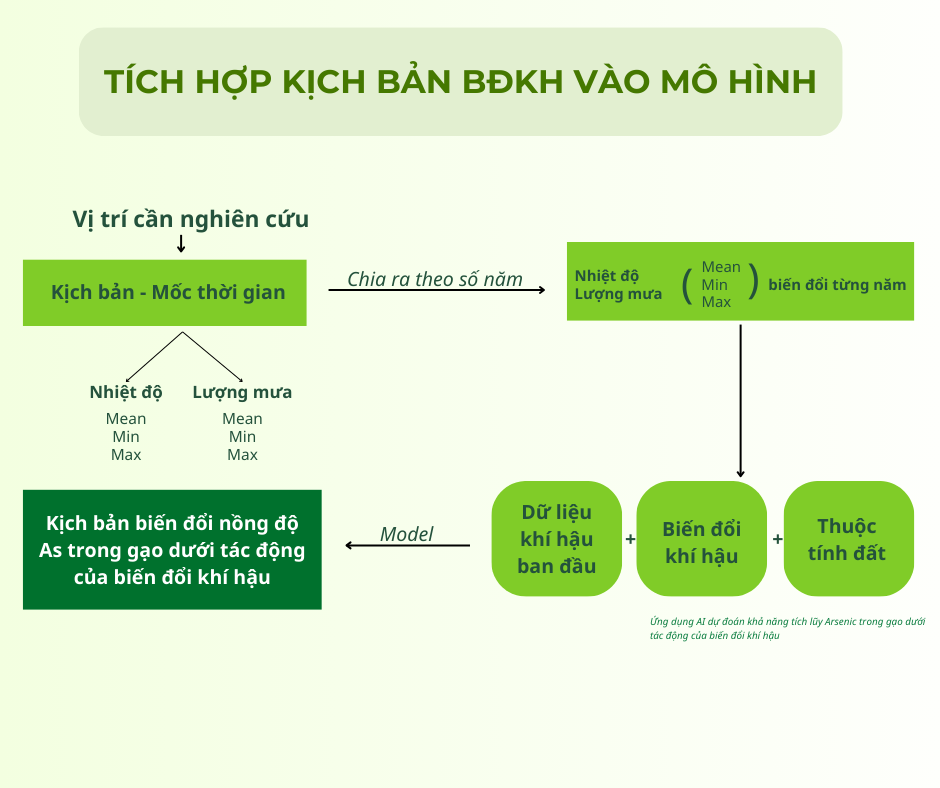
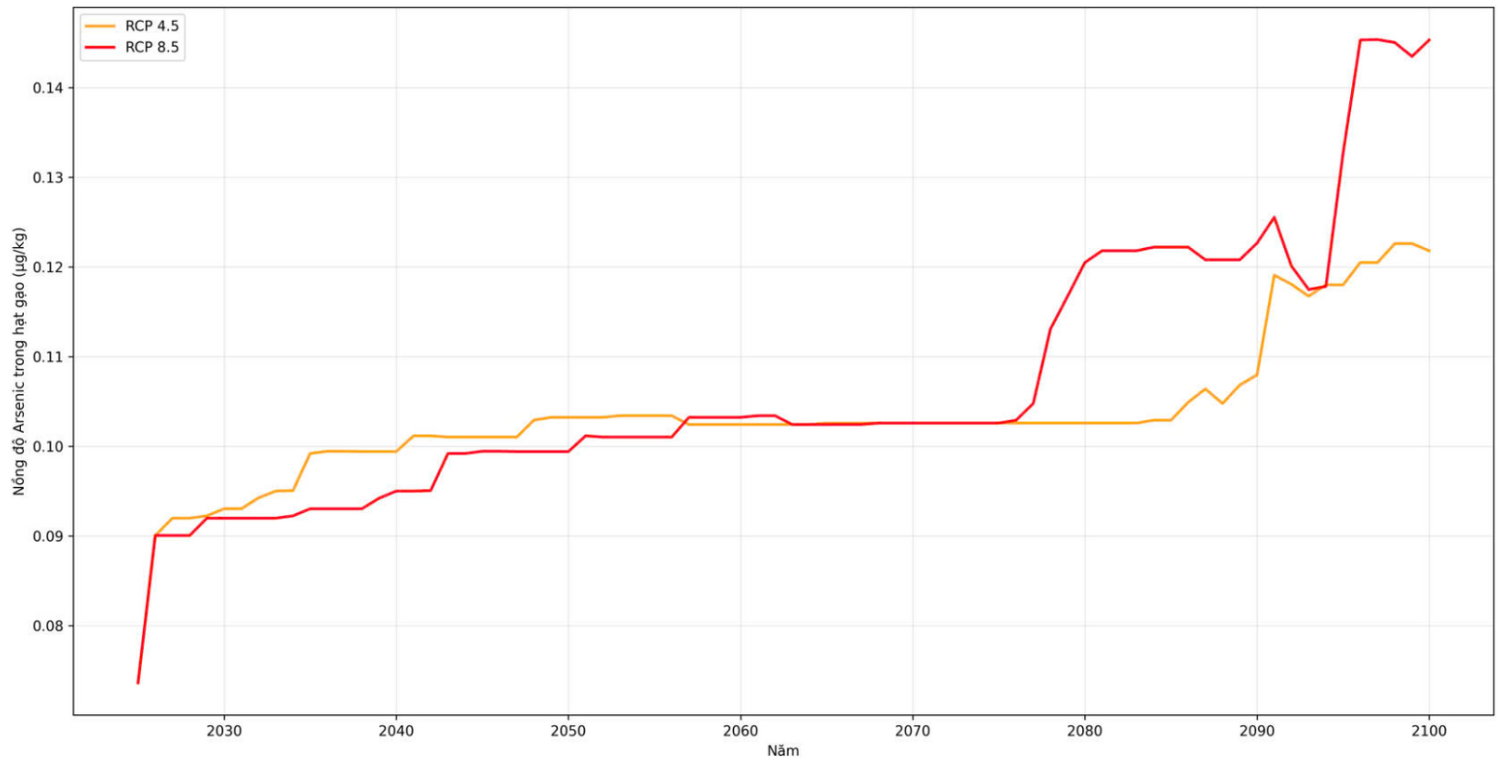
Nghiên cứu này sử dụng một bộ số liệu bao gồm thông tin về hàm lượng Asen trong đất,lúa, gạo, cùng với các dữ liệu chi tiết về các thuộc tính của đất, lúa, gạo và điều kiện khí hậu tại các vùng trồng lúa khác nhau ở Việt Nam.
Quy mô dữ liệu: 1.174 mẫu đất, lúa, gạo từ các vùng trồng lúa Việt Nam (2017-2024)
Phạm vi dữ liệu: Phân bố rộng khắp miền Bắc, Trung, Nam và trong cả hai mùa vụ chính
Nội dung dữ liệu:
- Nồng độ As trong đất và lúa, gạo
- Đặc tính hóa lý của gạo
- Đặc tính hóa lý của thân cây lúa
- Đặc tính hóa lý của đất
- Yếu tố khí hậu
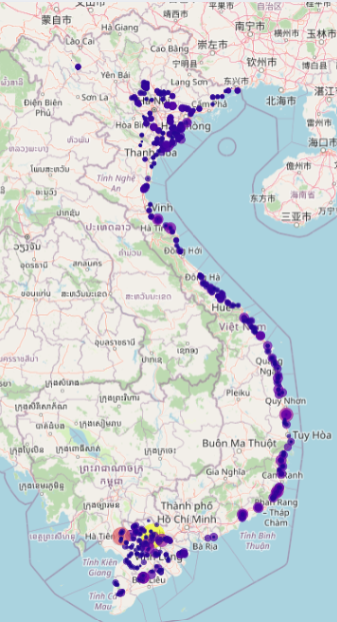
Bản đồ phân bố các điểm lấy mẫu trên khắp Việt Nam
Để chuẩn bị dữ liệu cho mô hình dự đoán nồng độ Asen trong gạo phải trải qua một quá trình tiền xử lý:
- Loại bỏ mẫu không có thông tin về nồng độ Asen trong gạo
- Loại bỏ outlier bằng phương pháp khoảng tứ phân vị (IQR)
- Điền giá trị còn thiếu bằng phương pháp MICE kết hợp Random Forest
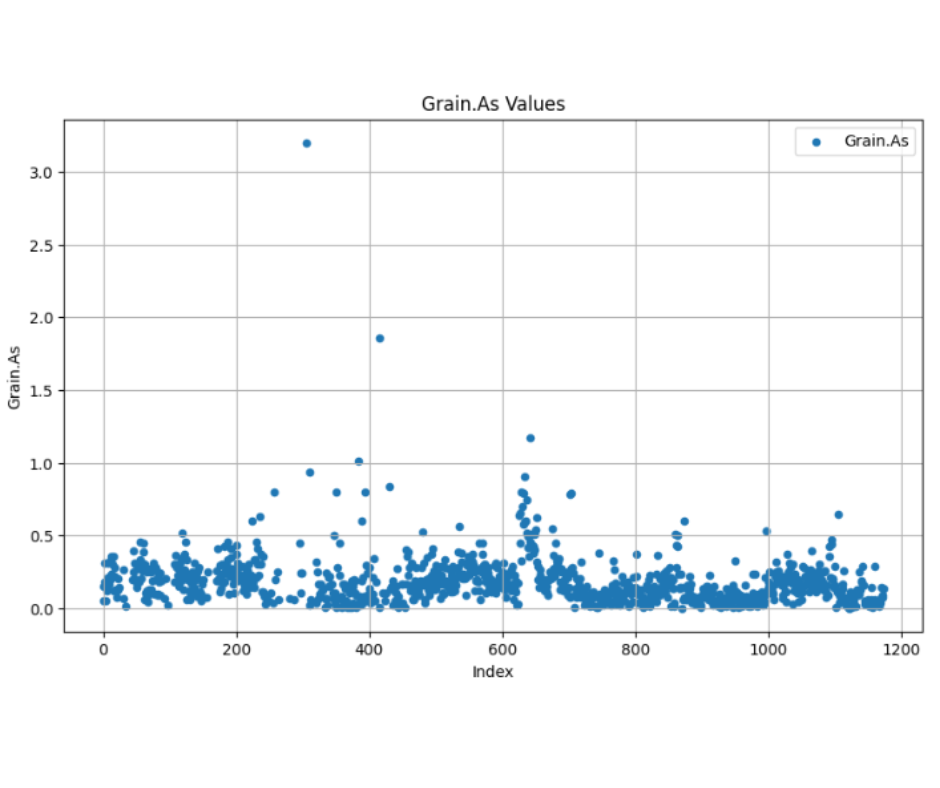
Dữ liệu trước xử lý
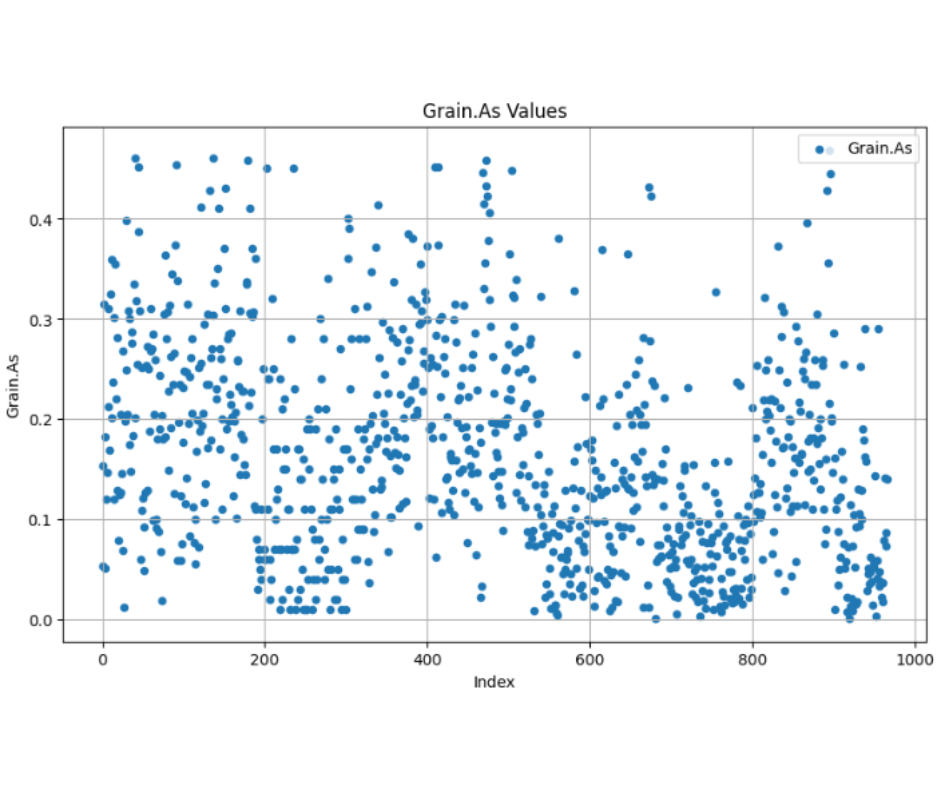
Dữ liệu sau xử lý
Nghiên cứu này ưu tiên sử dụng các mô hình học máy dựa trên cây quyết định (Decision Tree Regression) thay vì các phương pháp hồi quy tuyến tính truyền thống do nhiều ưu điểm vượt trội
- Khả năng mô hình hóa các mối quan hệ phi tuyến phức tạp
- Xử lý hiệu quả các tương tác đa chiều giữa các biến môi trường
- Tự động xác định các đặc trưng quan trọng mà không cần tiền xử lý phức tạp
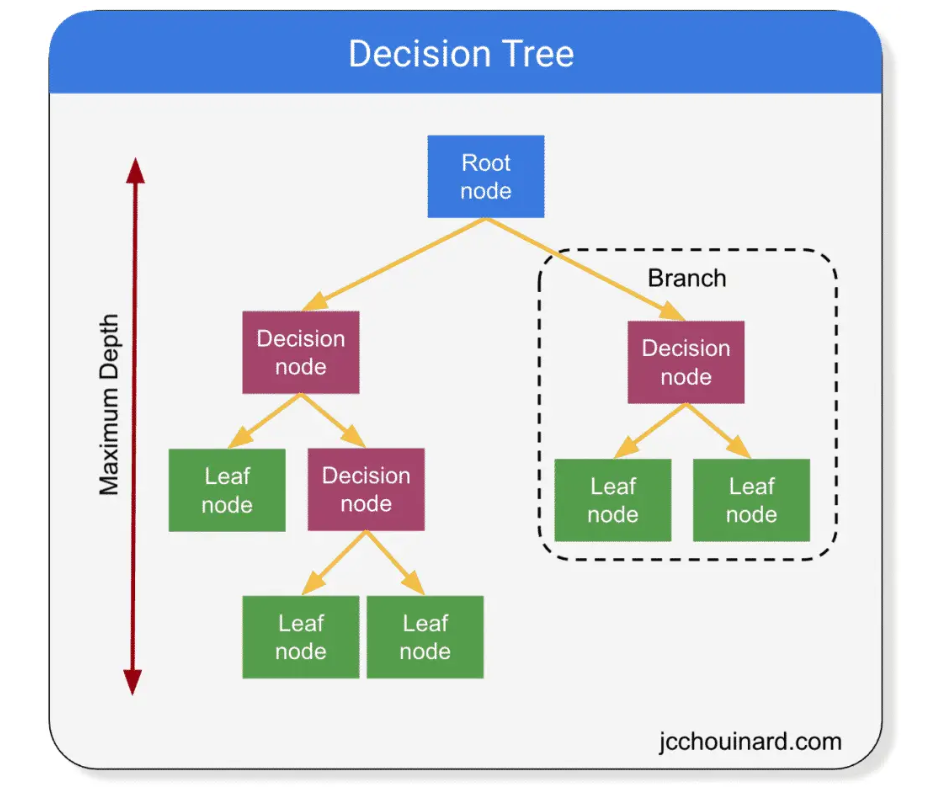
Ảnh minh họa cây quyết định
Nghiên cứu này sử dụng hai thuật toán phổ biến bao gồm:
RandomForest
Thuật toán xây dựng đồng thời nhiều cây quyết định độc lập trên các tập con bootstrap của dữ liệu. Mỗi cây sử dụng một tập con ngẫu nhiên của các đặc trưng tại mỗi nút phân chia, giúp tăng tính đa dạng của mô hình. Kết quả dự đoán cuối cùng là giá trị trung bình từ tất cả các cây con.
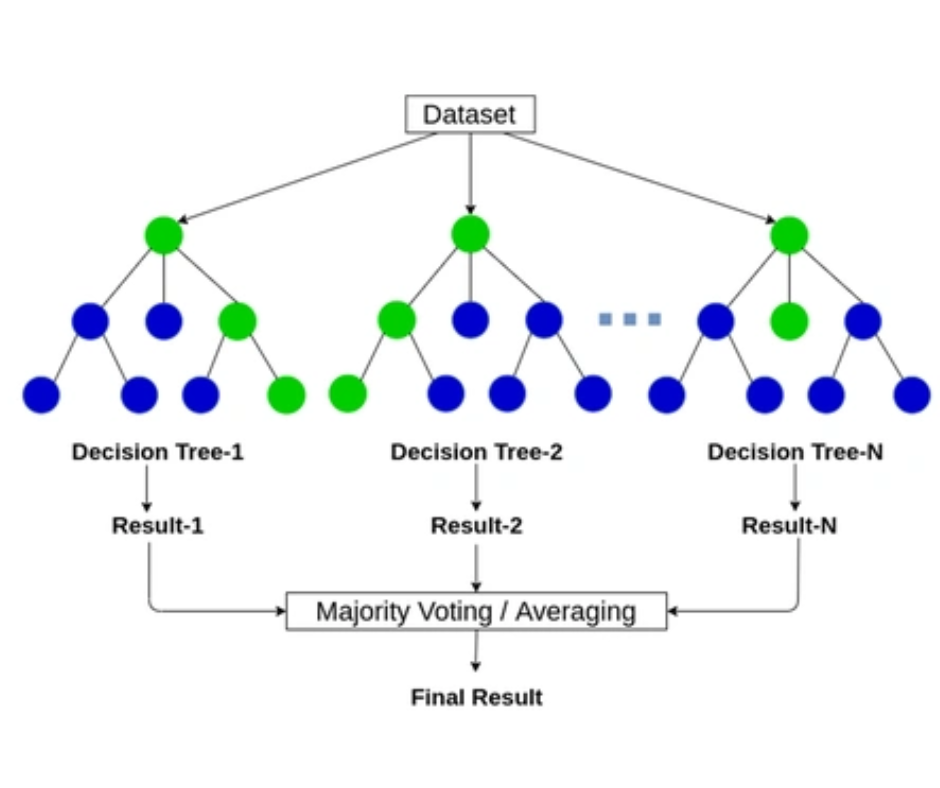
Ảnh minh họa mô hình Random Forest
XGBoost
Thuật toán ensemble dựa trên kỹ thuật boosting tuần tự, trong đó mỗi cây mới được xây dựng để khắc phục sai số của các cây trước đó. XGBoost tích hợp cơ chế chính quy hóa tiên tiến để ngăn chặn hiện tượng overfitting và sử dụng hệ thống tối ưu hóa có hiệu suất cao.
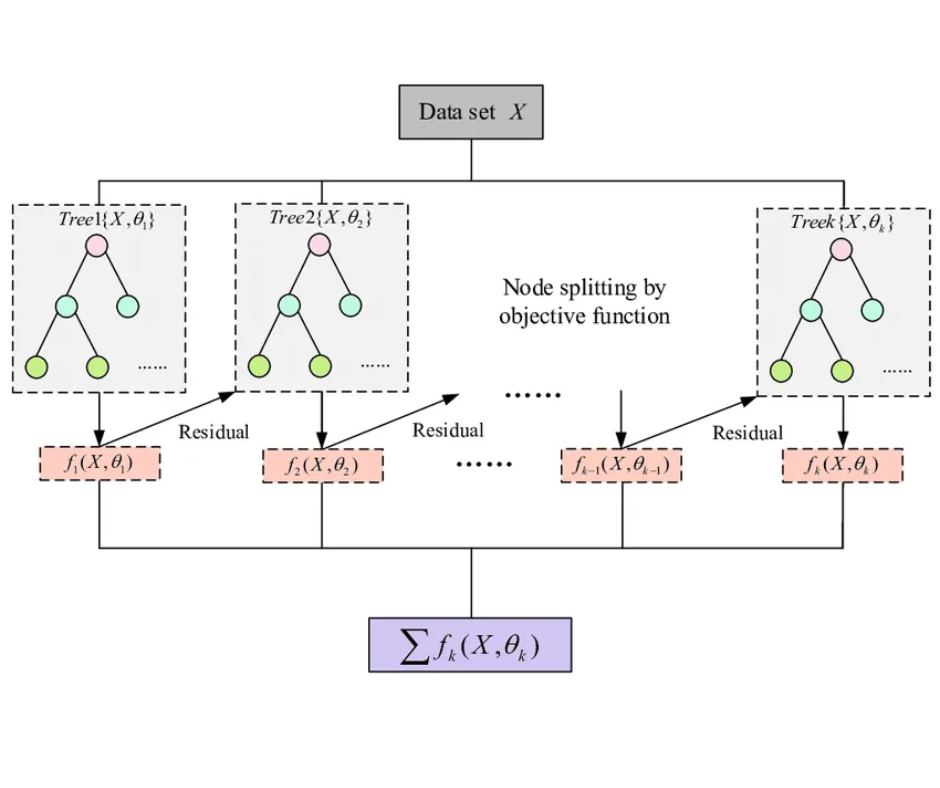
Ảnh minh họa mô hình XGBoost
Thang đo hiệu suất mô hình
R²: Đo tỷ lệ phần trăm biến thiên của biến mục tiêu được giải thích bởi mô hình. Giá trị từ 0 đến 1, càng gần 1 càng tốt.
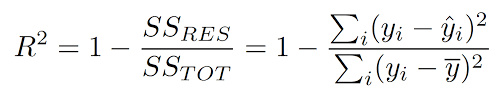
Công thức tính R²
RMSE : Đo lường độ lớn trung bình của sai số dự đoán, đơn vị tương đồng với biến mục tiêu. Giá trị RMSE càng thấp càng tốt.
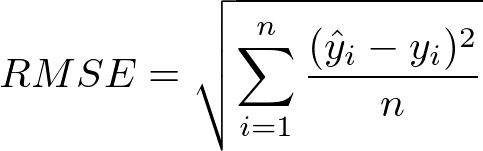
Công thức tính RMSE
So sánh hiệu suất các mô hình với các phương pháp truyền thống
| Mô hình |
Train RMSE |
Test RMSE |
Train R² |
Test R² |
| XGBoost |
0.028790 |
0.072668 |
0.923347 |
0.495532 |
| RandomForest |
0.049582 |
0.073197 |
0.772653 |
0.518263 |
| LinearRegression |
0.097342 |
0.101061 |
0.123733 |
0.088693 |
| RidgeRegression |
0.097342 |
0.101062 |
0.123732 |
0.088676 |
Kết quả cho thấy sự vượt trội rõ rệt của các mô hình dựa trên cây quyết định so với các phương pháp hồi quy tuyến tính. Cụ thể:
XGBoost và RandomForest đạt giá trị RMSE thấp hơn đáng kể và R² cao hơn nhiều lần so với Linear Regression và Ridge Regression cả trên tập huấn luyện và tập kiểm thử.
RandomForest thể hiện hiệu suất tốt nhất với Test R² ≈ 0.52, cho thấy mô hình có thể giải thích được gần 52% biến thiên nồng độ asen trong gạo dựa trên các yếu tố đầu vào.
Nâng cao hiệu suất dự đoán với Ensemble Learning
Sau khi xây dựng các mô hình cơ sở, nghiên cứu tiến hành áp dụng phương pháp Ensemble Learning để nâng hiệu suất dự đoán của mô hình tốt. Các phương pháp sử dụng bao gồm:
- Voting Ensemble: Kết hợp dự đoán bằng cách lấy giá trị trung bình từ các mô hình cơ sở
- Stacking Ensemble: Sử dụng dự đoán từ các mô hình cơ sở làm đầu vào cho một mô hình cấp cao hơn
- Weighted Ensemble: Kết hợp các dự đoán với trọng số tối ưu được xác định thông qua Ridge Regression
So sánh hiệu suất các mô hình với các phương pháp truyền thống
| Mô hình |
Train RMSE |
Test RMSE |
Train R² |
Test R² |
| XGBoost |
0.028790 |
0.072668 |
0.923347 |
0.495532 |
| RandomForest |
0.049582 |
0.073197 |
0.772653 |
0.518263 |
| Voting Ensemble |
0.055581 |
0.080807 |
0.714314 |
0.417365 |
| Stacking Ensemble |
0.039972 |
0.075881 |
0.852241 |
0.486245 |
| Weighted Ensemble |
0.037426 |
0.06831 |
0.870463 |
0.538847 |
Kết quả đánh giá cho thấy Weighted Ensemble nổi bật với chỉ số Test RMSE thấp nhất (0.06831) và Test R² cao nhất (0.538847), vượt trội hơn so với cả mô hình đơn lẻ và các phương pháp ensemble khác
Cuối cùng Weighted Ensemble được lựa chọn làm mô hình vì không chỉ đạt hiệu suất cao nhất mà còn dễ dàng triển khai trong thực tế